


Technology readiness levels for machine learning systems
Considerations for jobs relying on you to scale and deploy your AI/ML into engineering (eg simulation) environments

By now, you’ve probably seen very compelling demonstrations of AI/ML in simulation projects. However, many such compelling projects don’t leave the Python sandbox and make their way into industry projects (integrated environments with all the other design and simulation tools). For example, a ML prototype that looked amazing in a Jupyter notebook, only to “depart the runway” when you tried to bolt it onto a bigger simulation or flight-control stack.
If you’re a mechanical or aerospace engineer, you already know why: engineering projects live or die on processes—design reviews, verification & validation (V&V), risk matrices, configuration control. ML often skips those guard-rails, and has the risk to rack up technical debt along the way.
Whether you are A) looking to get a job with such responsibilities, or B) transitioning such proof of concepts into products, I hope this post will help you.
In my opinion, this is top of mind for many industry teams at present as we have seen remarkable progress in achieving more mature SciML technologies (like more advanced models, hardware, etc.). For example, in 2019 many of the publications were using simple machine learning models that required ~1-2k cases (simulations) to train on, with a lot of concession on the model’s ability to generalize and capture small but important patterns in the data (e.g. a tiny tip vortex in a large simulation). However currently, I would really only consider models competitive if they work reasonably well with under 100 samples to start (depending on the problem, of course).
I think an excellent blueprint for this post will be this publication in Nature on Technology Readiness Levels (TRL). Here is the paper. This post is a combination of my paraphrasing to this paper imbued with my own personal experience/thoughts.

I have gotten a high volume of feedback to review more papers like this, so I hope you enjoy.
I like this paper for us in simulation/physics based applications of AI/ML because it sets the stage of development and deployment of AI/ML systems in the context of spacecraft systems. This is refreshing, as we often see examples in ‘mainstream’ technologies like social media apps (Meta), recommendation systems (Netflix), or logistics/services (Uber Eats), which of course are outside our SciML realm.
“…we’ve developed a proven systems engineering approach for machine learning and artificial intelligence: the Machine Learning Technology Readiness Levels framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for machine learning workflows, including key distinctions from traditional software engineering, and a lingua franca for people across teams and organizations to work collaboratively on machine learning and artificial intelligence technologies”
Generally, we can point out a few (of many) challenges regarding integrating AI/ML technologies into our working environments (e.g. software):
Models/Algorithms are developed in isolation from real-world data/environments. For example, the model trained and created in a Python IDE, but in the wild the data would come from other applications (which vary from one instance to another). The details here make a difference.
We try our best, but models are trained and prepared on limited curated datasets, and we cannot anticipate all the future types of data it would receive. The better we can anticipate, the better we can put in ‘guard rails’ to ensure users have a good experience and models are accurate.
The nature of process is fundamentally different between engineering disciplines and AI/ML software workflows. Engineering disciplines have defined phases that each have strict timelines, linear progression, and review gates at each along the way (requirements definition, conceptual design, …, prototyping, deployment, end-of-life). Whereas the user experience in training AI/ML models is a workflow hinged on rapid iteration/fix/deployment. Big difference!
The Author’s Framework
The authors propose a framework: MLTRL. MLTRL “defines TRLs to guide and communicate machine learning and artificial intelligence development and deployment”
Remember, TRL is basically a label on how ready-for-use a given method (e.g. model, algorithm, software, procedure, etc.) is in the production activities pertaining to ‘making’ your equipment (e.g. designing your gas turbine engine). Low TRL means there are few details sorted, lots to validate, and perhaps it’s very early days in proving out a research concept. High TRL means it is ready to be used in the actual design methods involved in creating/designing your product.
In more specific detail, checkout the figure below from the paper. Remember, every company has their own flavor of TRL evaluation that they use, and this paper is providing a framework for us when our tools start to involve AI/ML models/software (which changes things up, and hence the value in such a publication).
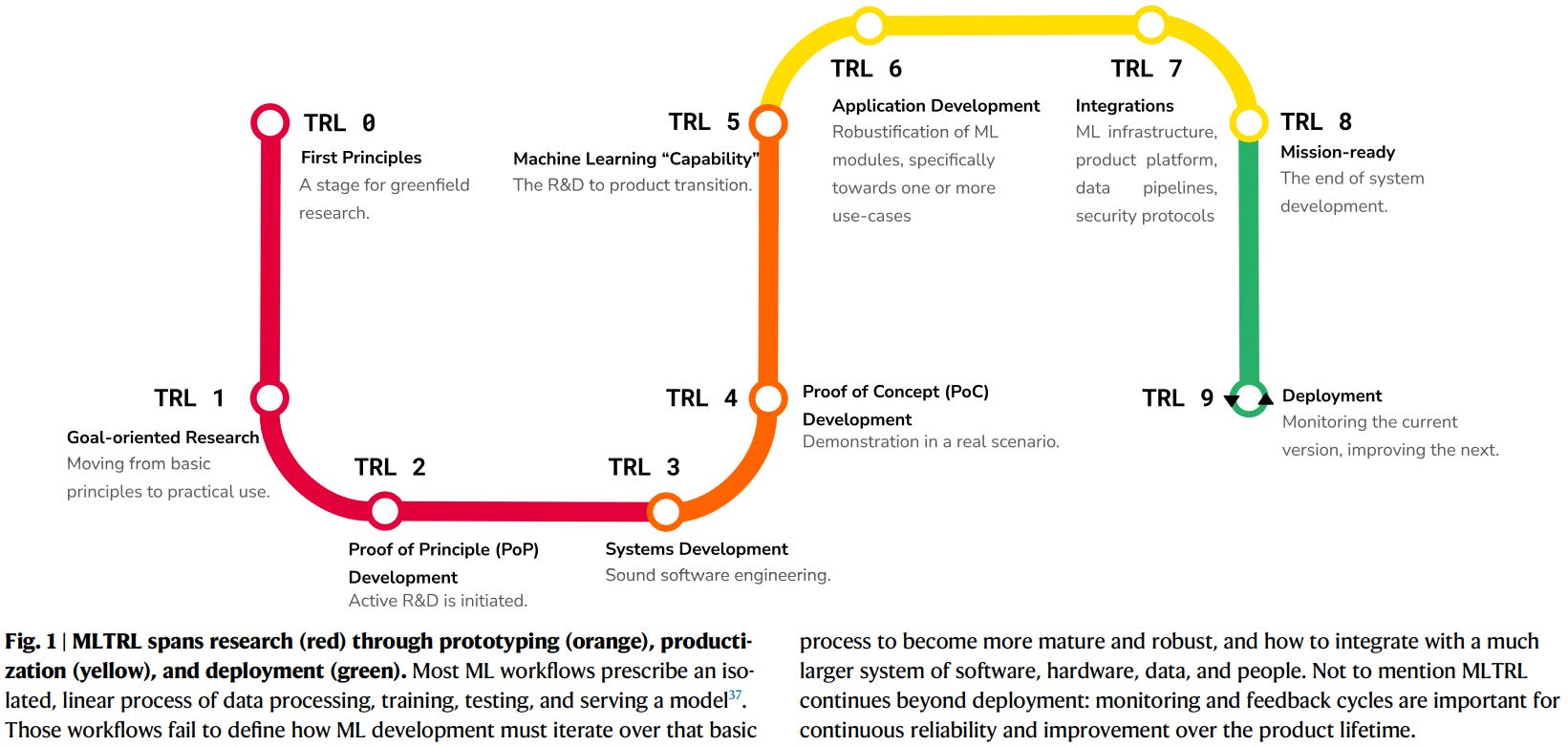
A few call-outs engineers will appreciate
Gated reviews at every level—think preliminary design review/critical design review equivalents but scaled for ML.
TRL Cards: snapshots capturing owners, data bias, corner-cases, and risk scores. These live throughout the project, not as after-the-fact documentation.
Risk = P(failure) × value baked into each technical requirement—like how aerospace already ranks hazards.
Here’s an example in the image below, from the author’s publication, to help this materialize into more concrete terms.

Switchbacks: failing forward on purpose
Real projects aren’t linear. MLTRL explicitly allows switchbacks—structured loops that bump a component down a level when new risks surface:
Discovery switchbacks (natural tech gaps emerge, Figure 3)
Review switchbacks (gate review says “not yet”, Figure 3).
Embedded switchbacks (pre-planned cycles, e.g. after first field data, FIgure 3).
You may recognize this as the difference between re-work and design iteration: by planning the loop, you avoid late surprises and hidden debt.
Data first, not code first
Every level spells out data chores—from curation strategies at L0 to governance and drift monitoring at L9. The authors hammer home that data is the moving part most likely to break a deployed ML pipeline, so you test it like any other flight-critical subsystem.
Resources!
There’s no code in the paper to share, but the authors share everything else:
For comparison, check out the NASA Technology Readiness Assessment Best Practices Guide here
Hope you enjoyed this one!