
Promising AI Foundation Models in Science: Examples with Code and Data
Papers & Code for Foundation Models in Science

In the most approachable terms, foundation models are a class of AI/ML models that are accurate and useful over a much more broad range of circumstances after training (often called inference). Often, you might have experienced a situation where you (or someone you know) trained a ML model with a certain dataset and the understanding was that the model is only going to give useful predictions on very similar data. Well, if you continue to train different and better AI/ML models until they become accurate over an increasingly different number of problems, well simply put you are moving in the direction ‘towards’ a foundation model (but it’s extremely difficult).
An example to help set the stage for readers before we nerd out about science:
Lets’ say I train a model that can classify ‘dog’ or ‘cat’ when shown an image of dogs and cats. Further, after improvements and intense training on all kinds of different animal images, the model is now able to tell you any animal in any picture you show it.
Several ‘vision models’ are widely treated as “foundational” for image classification because they’re pretrained at scale and then adapted for a wide variety of tasks (often with little or no task-specific data). Examples include BiT (Big Transfer) (reference publication) , CLIP (reference) , and multiple others.
After the overwhelming success of ChatGPT as a foundation model that works with language, whether it be a human or coding language, folks have turned to scientific applications and asked themselves an ambitious question:
Could a machine learning model truly learn a specific area of science?
If so, the possibilities are incredibly exciting as we humans have developed yet another powerful tool to advance our understanding of physics. However, like almost all good things, there has been false marketing by those that are either unaware of how machine learning really works or charlatans. This has brought confusion to the mainstream on an already complicated and (often) black-box technology.
In this blog, I focus on using machine learning models to predict scientific/engineering results and data. However, this is closely coupled to another very important topic that will shape industry in the future: “Industry Foundation Models”, which include models that can speak the language of a certain industry so well that it can dramatically accelerate the workforce (e.g. a faster time to market for a company designing a new car or product). Mainstream language models like ChatGPT fail today when inserted into industry teams for multiple reasons. To explain more about this kind of industrial foundation model, check this post.
I want to do two things here on this topic for the remainder of the blog:
Point you to my past blog post that clarifies the criteria you should use when judging ‘is this a foundation model’? This is extremely important to decipher the real capabilities of AI models (the vast majority are not even close to being a foundation model, and it’s important to recognize this).
Podcast: Defining Foundation Models for Computational Science: A Call for Clarity and Rigor

Enjoy this synthetic podcast on the paper:
(The remainder of this post) I want to share what I believe are examples of actual foundation model candidates for certain specific areas of science. Even my language here is carefully chosen - as the term ‘foundation model’ is immense and challenging to judge unilaterally.
Let’s start the review now of what I believe are good foundation model candidates across science and engineering domains. I loved writing this and finding hands-on code/papers for these, so I assure you there will be a ‘part 2’ on this topic.
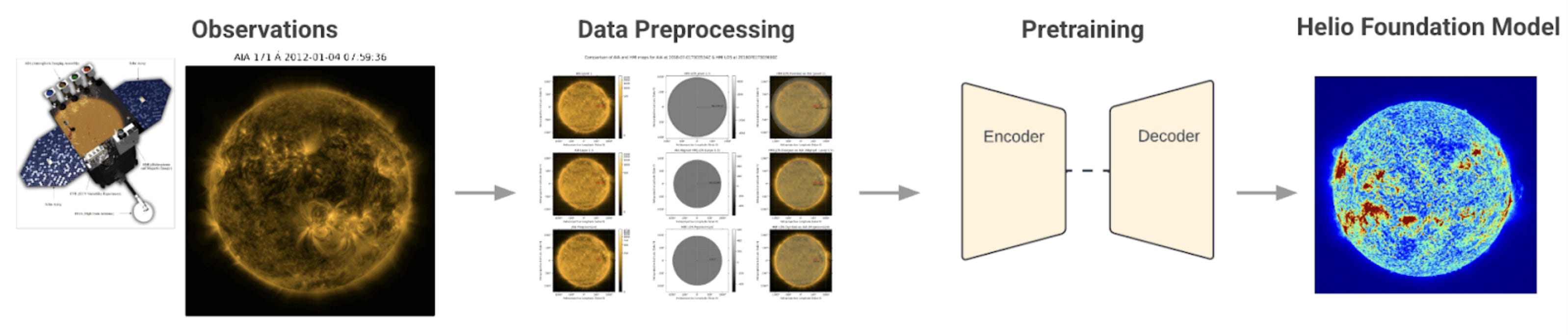
The First Heliophysics AI Foundation Model (by IBM and NASA)
Just two months ago, IBM and NASA released Surya; the most advanced open-source foundation model designed to understand high resolution solar observation data and predict how solar activity affects Earth and space-based technology [reference]. Trained on 9 years of historical data from NASA’s Solar Dynamics Observatory, Surya’s model accuracy beats existing benchmarks by 16%. This modeling is helping scientists better understand solar eruptions and predict space weather that threatens satellites, power grids, and communication systems [reference].

The code is available here on Hugging Face, which includes:
SuryaBench. Benchmark Dataset for Advancing Machine Learning in Heliophysics and Space Weather Prediction
5 (as of today) nasa-ibm-ai4science models (solar wind, solar flares, active region segmentation, …)
8 datasets
(other things)
If I was still in school I am sure I would deep dive into this as a portfolio builder 👇
Authors state that the architecture and methodology used are adaptable across other scientific domains! NASA has a broader initiative to develop open-access, AI-powered science tools (check out there page for such here). I actually think this is extremely interesting and I did not know about this before writing this article. The Office of the Chief Science Data Officer (OCSDO) at NASA is collaborating across their five science divisions and making a foundation model for each division. Further, they are creating a language model that will competently jump between the different disciplines, allowing cross-disciplinary work.

Some of the foundation models included appear to be under development and thus less publicized, but here is another; the “Prithvi” family (Link 🔗). It is a set of AI foundation models for Earth observation, weather and climate, developed jointly by IBM and NASA. Examples of how it is being used could be to predict land use change, flood mapping, crop yield prediction, and more. Blog article here.

Generating Marine Vessel Designs (Hulls)
While there is fierce debate on how feasible it is to achieve a foundation model in different domains of science, (for good reason as it is quite a big claim) what both sides in the debate usually can agree on is that advanced AI/ML models could be pre-trained on massive amounts of data, for one specific problem in one specific industry, and then do relatively well out of the box for other problems in that domain.
Compute Maritime’s NeuralShipper™ product is a great example of achieving excellence like this with machine learning. It gives the automatic parametrization of any given hull form and generates valid designs in minutes. This model collaborates interactively with naval architects and designers, enabling them to quickly explore hundreds of hull forms.
“…NeuralShipper™, the world’s first GenAI tool capable of designing, simulating and optimising any type of ship hull. The model is trained on more than 100,000 designs of container ships, tankers, bulk carriers, tugboats, crew supply vessels, OSVs, CTVs, etc. [source & reference].

It may be hard to fully appreciate the engineering challenge if you are not in the field, but in essence there are a lot of considerations/competing criteria in designing such a vessel hull. This traditionally is addressed by hands-on engineering expertise, not easily automated, on a case by case basis. When the right ML architecture meets a huge dataset of relevant hull designs it is a union that is set to have a large impact on the maritime industry designs their ships. The impact is huge, especially considering that water transport is responsible for approximately 90% of global trade.
𝗔 𝗧𝗶𝗺𝗲 𝗦𝗲𝗿𝗶𝗲𝘀 Forecasting 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 𝗕𝘆 𝗚𝗼𝗼𝗴𝗹𝗲
Google Research has developed ‘TimeFM’, which was pre-trained on a large set of time series data (approximately 100 billion data points). The sentiment on performance is quite positive over various benchmarks from different domains.
Here is the publication link. The TimesFM model is available on HuggingFace and GitHub.
In their blog, one of my favorite passage to describe this model is as follow:
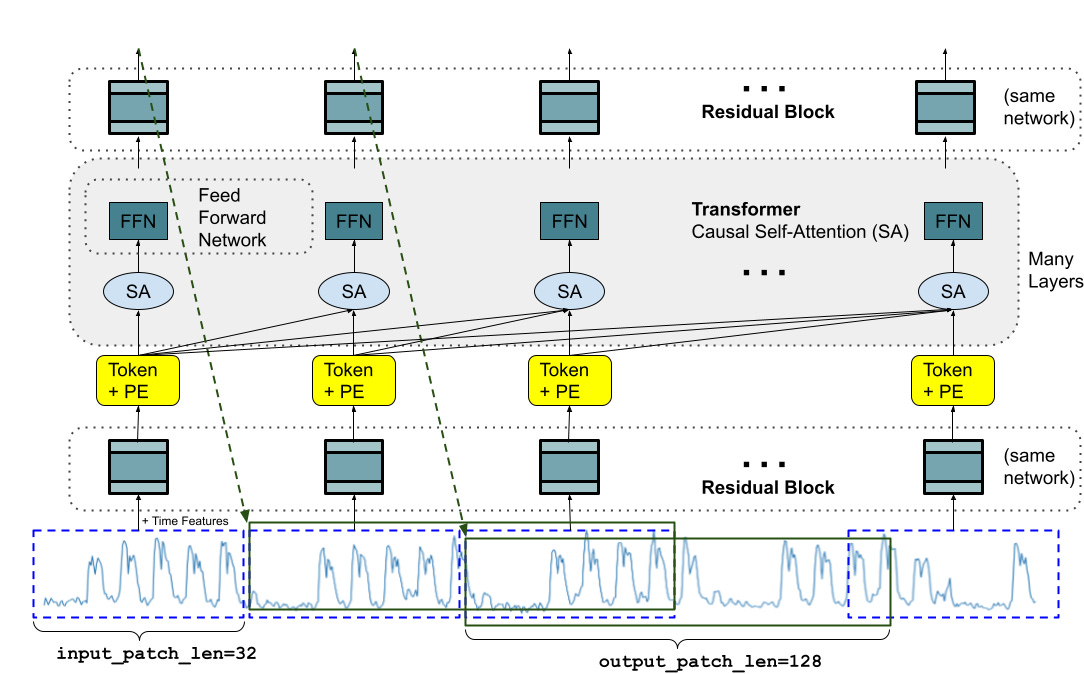
“A foundation model for time-series forecasting should adapt to variable context (what we observe) and horizon (what we query the model to forecast) lengths, while having enough capacity to encode all patterns from a large pretraining dataset. Similar to LLMs, we use stacked transformer layers (self-attention and feedforward layers) as the main building blocks for the TimesFM model. In the context of time-series forecasting, we treat a patch (a group of contiguous time-points) as a token that was popularized by a recent long-horizon forecasting work. The task then is to forecast the (i+1)-th patch of time-points given the i-th output at the end of the stacked transformer layers.
However, there are several key differences from language models. Firstly, we need a multilayer perceptron block with residual connections to convert a patch of time-series into a token that can be input to the transformer layers along with positional encodings (PE). For that, we use a residual block similar to our prior work in long-horizon forecasting. Secondly, at the other end, an output token from the stacked transformer can be used to predict a longer length of subsequent time-points than the input patch length, i.e., the output patch length can be larger than the input patch length.”
/Part-1-End
I really enjoyed digging through these models and looking forward to sharing at least 3 more in the next post. Also, I notice some trends among the different models and keen to discuss them.
Thanks for being here!